Proxmox VE(PVE) 安裝相關紀錄
- 版本資訊(Roadmap) - https://pve.proxmox.com/wiki/Roadmap
更改 Package Repositories
- PVE 8
- PVE 7
- PVE 6
- PVE 5
載入中 ...
PVE 8
- /etc/apt/sources.list
deb http://ftp.tw.debian.org/debian bookworm main contrib deb http://ftp.tw.debian.org/debian bookworm-updates main contrib deb http://download.proxmox.com/debian/pve bookworm pve-no-subscription # security updates deb http://security.debian.org bookworm-security main contrib
- /etc/apt/sources.list.d/pve-enterprise.list
#deb https://enterprise.proxmox.com/debian/pve bookworm pve-enterprise
- /etc/apt/sources.list.d/ceph.list
#deb https://enterprise.proxmox.com/debian/ceph-quincy bookworm enterprise
執行命令列更新
apt update apt upgrade
PVE 主機安裝 snmpd
- 安裝與設定程序
apt install snmpd -y cd /etc/snmp/ mv snmpd.conf snmpd.conf.org vi snmpd.conf : 依照實際需要編輯 : service snmpd restart systemctl enable snmpd
如有使用 ZFS 可限制使用記憶體大小
PVE 主機設定 Postfix 由 GMail 寄發信件方式
- 假設預計 Relay 的 SMTP Server - smtp.gmail.com:587 (STARTTLS) 認證帳號:username 密碼:password
- 安裝相關套件
apt install libsasl2-modules -y - 編輯 /etc/postfix/main.cf
: # GMail Setting relayhost = [smtp.gmail.com]:587 # use tls smtp_use_tls=yes # MailU Setting #relayhost = [mail.mailu.com]:465 #smtp_tls_security_level = encrypt #smtp_tls_wrappermode = yes # use sasl when authenticating to foreign SMTP servers smtp_sasl_auth_enable = yes # path to password map file smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd # list of CAs to trust when verifying server certificate smtp_tls_CAfile = /etc/ssl/certs/ca-certificates.crt # eliminates default security options which are imcompatible with gmail smtp_sasl_security_options = noanonymous smtp_always_send_ehlo = yes
- 編輯 /etc/postfix/sasl_passwd
[smtp.gmail.com]:587 username:password #[mail.mailu.com]:465 username:password
- 更改檔案權限
newaliases postmap /etc/postfix/sasl_passwd cd /etc/postfix chown postfix /etc/postfix/sasl_passwd*
- 讓 postfix 新設定生效
/etc/init.d/postfix reload
- 如果 Google 的帳號有設定二階段認證, 密碼的部份就必須到 Google 帳號產生應用程式密碼


移除 cluster 內的一個 node
-
- 先進入 cluster 內其中一台 (不能是 pve01)
- 執行以下的語法將 pve01 刪除
pvecm nodes pvecm delnode pve01 pvecm status rm -rf /etc/pve/nodes/pve01
- 進入每個 node 將 pve cluster 服務重新啟動
systemctl restart corosync systemctl restart pve-cluster
- 設定相同 IP 或 hostname 加入 Cluster 後, 因為之前的 ssh fingerprint / authorized_keys 在各節點都還有殘存, 所以需要在新增的節點上執行以下命令
pvecm updatecerts - 可以直接編輯 /etc/pve/priv 內的 known_hosts 與 authorized_keys 將已經不在 cluster 內的 node ip 紀錄移除
- 再至所有 cluster 內 node 的 /root/.ssh/ 內 known_hosts 將已經不在 cluster 內的 node ip 紀錄移除
一個新安裝 node 加入 cluster
透過 Web 介面直接加入會比較簡單, 以下是針對無法呈現 Web 時透過命令列方式處理的程序
- Exp. pve02 加入 cluster, 這 cluster 其中一個 node 是 192.168.11.250
- 進入 pve02 主機內, 執行以下指令
pvecm add 192.168.11.250 - 會出現需要輸入 192.168.11.250 內的 root 密碼
- 如果沒有異常訊息就完成加入 cluster
無法加入通常會顯示出原因, Exp.
- corosync 服務是啟動狀態
- 認證 key 已經存在… 等等
有主機故障, 出現 no quorum 問題的處理方式
- 因為預設 cluster 的 quorum 要兩個才能運作, 所以如果兩台的 cluster 壞了一台, 一段時間後就會出現這樣的問題, 如果想讓還正常的主機啟動 vm / ct , 可以將 quorum 的限制改成 1 , 然後重起 clusrter 服務即可, 手動解決方式如下:
pvecm expected 1 service pve-cluster restart
移除 Cluster 的方式
- https://pve.proxmox.com/wiki/Cluster_Manager
pvecm nodes systemctl stop pve-cluster systemctl stop corosync pmxcfs -l rm /etc/pve/corosync.conf rm -rf /etc/corosync/* killall pmxcfs systemctl start pve-cluster
更改 hostname 方式
更改主機 IP 方式
- 參考 - pve-42-cluster-修改方式
- Web UI 更改 IP : System→Network→ 選定介面卡 → Edit
- 更改 /etc/hosts 內的 IP
- 關閉 cluster 服務
service pve-cluster stop - 修改 /etc/pve/corosync.conf 內 node ip 與 totem 內的 ip
- 重新開機
設定 SSD 硬碟當 Swap Memory 方式
- 當 PVE 系統安裝在 USB or HD 上時, 預設會將 Swap Memory 指定在其中的一個 Partition 上, 導致使用到 Swap Memory 效能會變很差
- 先查看目前系統記憶體使用狀況
free -m swapon -s
建立 Linux Swap 方式
- 假設 SSD 所在 /dev/sdc , 透過 fdisk 建立 16GB 的 Swap Memory Partition
fdisk /dev/sdc- 建立 16GB Partition
Command (m for help): n Partition number (1-128, default 1): 1 First sector (34-937703054, default 2048): Last sector, +sectors or +size{K,M,G,T,P} (2048-937703054, default 937703054): +16G
- 更改 type 為 Linux Swap
Command (m for help): t Selected partition 1 Hex code (type L to list all codes): 19 Changed type of partition 'Linux swap' to 'Linux swap'.
- 檢視與寫入
Command (m for help): p : /dev/sdc1 2048 33556479 33554432 16G Linux swap : Command (m for help): w : Syncing disks.
- 使用 mkswap 讓系統知道 /dev/sdc1 是 Swap Memory Partition
mkswap /dev/sdc1 - 讓 /dev/sdc1 的 Swap Memory 立即生效
swapon /dev/sdc1 - 使用 swapon -s 列出目前的 Swap Memory
: /dev/zd0 partition 8388604 434944 -2 /dev/sdc1 partition 16777212 0 -3
- 確認 /dev/sdc1 的 id
blkid | grep swap /dev/sdc1: UUID="068ba285-5bb9-4b2f-b2e1-4dc599bd22e1" TYPE="swap" PARTUUID="1d334105-c76e-4ab2-baec-2b35fde71a02" /dev/zd0: UUID="a06df01d-bf15-4816-bc3e-f1d3c623ff20" TYPE="swap"
- 關閉原本 /dev/zd0 的 swap memory 設定, 修改
- /etc/fstab
: #/dev/zvol/rpool/swap none swap sw 0 0 UUID=068ba285-5bb9-4b2f-b2e1-4dc599bd22e1 none swap sw 0 0 :
- 重新啟動 pve node
sync;sync;sync;reboot
建立 ZFS Swap 方式
- 假設 SSD 所在的 zfs pool 為 rpool
- 關閉所有swap:
swapoff -a - 建立 16GB ZFS swap:
zfs create -V 16G -b $(getconf PAGESIZE) -o compression=zle \ -o logbias=throughput -o sync=always \ -o primarycache=metadata -o secondarycache=none \ -o com.sun:auto-snapshot=false rpool/swap
- 格式化swap分區:
mkswap -f /dev/zvol/rpool/swap - 增加新的swap到 /etc/fstab :
echo /dev/zvol/rpool/swap none swap defaults 0 0 >> /etc/fstab - 啟用所有swap:
swapon -av - 調整Swap優先權:
echo "vm.swappiness = 10" >> /etc/sysctl.conf sysctl -p
加入一顆 LVM thin 的硬碟方式
-
- 透過 pvcreate/vgcreate 建立 VG Exp. vg-ssd
pvcreate /dev/sdb1 vgcreate vg-ssd /dev/sdb1 vgdisplay vg-ssd
- 因為 LVM thin 需要一些 VG 空間(至少 30 PE), 所以建立 lv 時必須保留 VG 一些空間給 LVM thin pool 使用 Exp. VG Free PE / Size 76310 / 298.09 GB, 保留 100 PE : 76310-100=76210
lvcreate -l 76210 -n ssd vg-ssd - 將 LVM 轉換成 LVM thin
lvconvert --type thin-pool vg-ssd/ssd - 再透過 PVE web 介面 Datacenter → Storage → Add → LVM-Thin
- 輸入 ID Exp. ssd
- 選擇 Volume group : vg-ssd
- Thin Pool : ssd
- 這樣就可以加入 LVM-Thin 的磁碟
- 移除 lvm 的方式 Exp. 以下所建立的 vg-ssd
- pvcreate /dev/sdb1
- vgcreate vg-ssd /dev/sdb1
- vgdisplay vg-ssd
vgremove vg-ssd pvremote /dev/sdb1
加入一顆 ZFS 的硬碟方式
將一顆實體 硬碟 加入 VM 使用
-
- 先確認實體硬碟的廠牌、型號與序號
ls -l /dev/disk/by-id/ | grep ata-* - 確認要加入的實體硬碟連結 Exp. ata-TOSHIBA_DT01ACA300_Z3MH9S1GS
- 加入 VM Exp. VM 編號 106
qm set 106 -virtio2 /dev/disk/by-id/ata-TOSHIBA_DT01ACA300_Z3MH9S1GS - 檢查是否 VM 106 的設定檔有出現實體硬碟設定
cat /etc/pve/qemu-server/106.conf : virtio2: /dev/disk/by-id/ata-TOSHIBA_DT01ACA300_Z3MH9S1GS,size=2930266584K
- 關閉 VM , 再透過 PVE Web 介面重新啟動
直接使用 virt-install 建立的 CentOS6 VM Image 開機程序過久問題
- 主要問題是在 pve 建立一個新的 VM 時, 預設並不會加入 serial 虛擬裝置, 造成原本的 CentOS6 VM Image 在開機過程中一直出現 press any key to continue 嘗試到最後才會跳過進入登入畫面
- 解決方式 -


migration 出現 No such cluster node 問題
- 主要問題是 vm 目前的主機端認為遷移目標主機有問題, 所以出現這樣的訊息..
- 解決方式 - 連入遷移主機可以看到目標主機是離線狀態(實際上並沒有離線), 所以要重新啟動 pve-cluster corosync 服務
systemctl restart pve-cluster corosync
migration 出現 volume 'xxx' already exists 問題
- 主要問題是 vm/ct 的硬碟檔名已出現在遷移目標的主機內, 所以出現這樣的訊息.. 可能之前遷移過程失敗沒有正確移除, 或是之前所建立的 vm/ct 移除時的硬碟沒有移除所造成硬碟檔名重複
- 解決方式 - 連入遷移主機將檔案移除即可, 如果是 zfs 可以使用 zfs destroy 方式移除, Exp. local-zfs/subvol-109-disk-1 是出現重複的硬碟
root@aac:~# zfs list NAME USED AVAIL REFER MOUNTPOINT local-zfs 9.60G 889G 128K /local-zfs local-zfs/subvol-103-disk-0 522M 7.49G 522M /local-zfs/subvol-103-disk-0 : local-zfs/subvol-109-disk-1 2.99G 5.01G 2.99G /local-zfs/subvol-109-disk-1 : local-zfs/subvol-131-disk-0 2.31G 13.7G 2.31G /local-zfs/subvol-131-disk-0 rpool 1.32G 227G 104K /rpool rpool/ROOT 1.32G 227G 96K /rpool/ROOT rpool/ROOT/pve-1 1.32G 227G 1.32G / rpool/data 96K 227G 96K /rpool/data root@aac:~# zfs destroy -r local-zfs/subvol-109-disk-1
migration 出現 Host key verification failed 問題
- 主要是 ssh 遠端免密碼登入認證檔出現異常問題.
- 解決方式 - 依據錯誤訊息提示的命令語法重新執行一次 Exp. migration 出現的錯誤訊息
2018-08-30 12:34:47 # /usr/bin/ssh -e none -o 'BatchMode=yes' -o 'HostKeyAlias=pve-45' [email protected] /bin/true 2018-08-30 12:34:47 Host key verification failed. 2018-08-30 12:34:47 ERROR: migration aborted (duration 00:00:00): Can't connect to destination address using public key TASK ERROR: migration aborted
登入 PVE 主機執行以下語法
root@pve-55:/etc/pve/priv# /usr/bin/ssh -e none -o 'HostKeyAlias=pve-45' [email protected] /bin/true The authenticity of host 'pve-45 (192.168.1.45)' can't be established. ECDSA key fingerprint is SHA256:NtU1vxeu32E9nXdhI8rjjRIxxAisGZRo/pmpW630XGk. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'pve-45' (ECDSA) to the list of known hosts.
- 如果是因為之前有移除與新增設定相同 IP 或 hostname 的節點, 因為之前的 ssh fingerprint / authorized_keys 在各節點都還有殘存, 所以需要在新增的節點上執行以下命令
pvecm updatecerts
online migration 使用本機硬碟的 VM
PVE 6.2 之後就完整支援 VM local Disk online migration 功能
已不須特別使用以下語法處理
已不須特別使用以下語法處理
- PVE Cluster 內的 node 有相同名稱的 Local Storage Exp. ssd-zfs
- VM 不能設定 Replication 設定
- 在 VM 所在的節點 shell 下以下的命令
qm migration <vmid> <目標節點名稱> --with-local-disks --online
Exp. VM 原本在節點 TP-PVE-250 , vmid: 104 , 目標節點名稱: TP-PVE-249 , 在 TP-PVE-250 節點 shell 下以下命令
root@TP-PVE-250:~# qm migrate 104 TP-PVE-249 --with-local-disks --online
- 會出現先將 VM Disk 複製過去目標節點, 之後會將記憶體資料同步過去目標節點, 才完成切換, 所以 VM Disk 如果愈大, 遷移時間就會愈久
migration 使用第二張網卡的設定方式
- 因為 migration 過程可能會需要使用大量頻寬, 所以指定走另外一個網卡介面應該會比較合適
- Exp. 第二張網卡網路的 Subnet 是 192.168.100.0/24 , 所以直接修改
vi /etc/pve/datacenter.cfg: migration: secure,network=192.168.100.0/24
設定使用 iSCSI 的 LVM Storage 方式
- 先確認已經有 iSCSI 的分享來源 Exp. FreeNAS IP: 192.168.11.246
- 登入 PVE Node 掛載 iSCSI Volume
- 先確認 iSCSI 分享的 target
iscsiadm -m discovery -t sendtargets -p 192.168.11.246 192.168.11.246:3260,-1 iqn.2005-10.org.freenas.ctl:freenas
- 登錄 iSCSI target
iscsiadm -m node -T iqn.2005-10.org.freenas.ctl:freenas -p 192.168.11.246 -l Logging in to [iface: default, target: iqn.2005-10.org.freenas.ctl:freenas, portal: 192.168.11.246,3260] (multiple) Login to [iface: default, target: iqn.2005-10.org.freenas.ctl:freenas, portal: 192.168.11.246,3260] successful.
- 設定開機可以自動登錄 iSCSI
iscsiadm -m node -p 192.168.11.246 -o update -n node.startup -v automatic - 如果有其他 PVE Node 每一台都執行以上兩個步驟
如果 iscsi 的連線要移除, 語法如下
iscsiadm -m node -T iqn.2005-10.org.freenas.ctl:freenas -p 192.168.11.246 -o delete
- 將 iSCSI 的 Volume 建立成為 LVM partition
- 執行後可以使用 fdisk -l 看到 PVE Node 多出來一個 Disk Exp. /dev/sdg
fdisk -l
: Disk /dev/sdg: 500 GiB, 536870912000 bytes, 1048576000 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 131072 bytes I/O size (minimum/optimal): 131072 bytes / 1048576 bytes
- 使用 fdisk /dev/sdg 建立 LVM partition
fdisk /dev/sdg- Command (m for help): g (建立GPT Partition Table)
- Command (m for help): n (建立新的 Partition )
- Command (m for help): t (更改 Type 為 31 Linux LVM)
- Command (m for help): p (列出新建立的 Partition 是否正確)
- Command (m for help): w (沒問題就 w 寫入)
- 使用 pvcreate 建立 LVM 的 Physical Volume(PV)
pvcreate /dev/sdg1 - 使用 vgcreate 建立 LVM 的 Volume Group (VG)
vgcreate vg-pve /dev/sdg1 - 在 PVE Web UI → Datacenter → Storage → Add → LVM
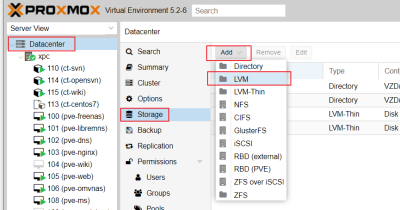
- 在彈出的 Add:LVM 視窗內
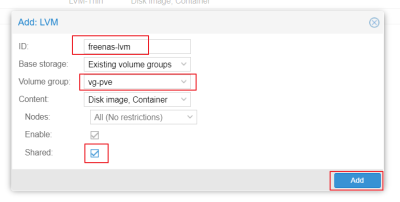
- 填入 ID Exp. freenas-lvm
- 選擇剛剛建立的 vg-pve
- 將 Shared 打勾
- 點下 Add
- Datacenter → Storage 內就可以看到增加 freenas-lvm 的項目


- iSCSI + LVM 會出現無法對 VM 進行 snapshot 問題, 主要是 LVM 不支援 live-snapshot
- 參考 PVE 官網整理 Storage 特性 - https://pve.proxmox.com/wiki/Storage
- 參考網址 :
CT(lxc) 設定掛載 CIFS 網路磁碟方式
- 這問題主要是預設建立 CT 會是 UnPrivilegied 模式, 所以建立時必須要將 UnPrivilegied 打勾拿掉
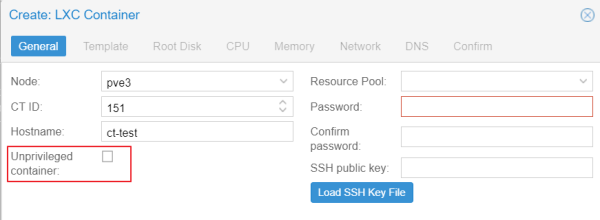
- 建立之後還要將 Features 的 CIFS 打勾

- 這樣就可以將 cifs 掛載上去 Exp.
cat /etc/fstab # UNCONFIGURED FSTAB FOR BASE SYSTEM //10.20.0.131/data/template/iso/ /omv-iso cifs username=isouser,password=xxxx,rw,users,dir_mode=0777,file_mode=0777 0 0


- 參考網址 :
中斷 Backup 的處理方式
- 正常只要透過 UI 的 Tasks→點開正在 Backup 的項目→Stop 即可中斷
- 但有時無法順利中斷, 或是中斷後對 VM 進行操作時出現 TASK ERROR: VM is locked (backup) 的錯訊息
- 可以在PVE主機端透過以下語法進行: Exp. VM id = 111
vzdump -stop ps -ef | grep vzdump qm unlock 111
- 參考網址 :
對備份到共用目錄 exp. NFS 無法中斷的處理方式
- 先確認 vzdump 程式是否 stat 出現 'D'(已經是 uninterruptible sleep 狀態) Exp.
root@PVE-13:~# ps ax | grep vzdump 2991321 ? Ds 0:01 task UPID:PVE-13:002DA4D9:064C84B2:6598045A:vzdump::root@pam: 3158042 pts/0 S+ 0:00 grep vzdump
如果 stat 有出現 D 的狀態, 原則上需要重開機才能砍掉
- 如果不想重開機, 可以試看看強制卸載該 node 的共用目錄後, 再中斷 vzdump 的 Workaround 方式, Exp.
root@PVE-13:/# cd /mnt/pve root@PVE-13:/mnt/pve# ls omv-nfs NFS-13 root@PVE-13:/mnt/pve# umount -f /mnt/pve/NFS-13 umount.nfs4: /mnt/pve/NFS-13: device is busy root@PVE-13:/mnt/pve# umount -f -l /mnt/pve/NFS-13 && vzdump --stop root@PVE-13:/mnt/pve# ps -ef | grep vzdump root 3158849 3019745 0 06:26 pts/0 00:00:00 grep vzdump
設定自動 Snapshot 的方式
- ZFS 雖然可以自動建立很多份 Snapshot, 但是只能還原最近的一次 Snapshot
- 使用套件 eve4pve-autosnap
- 安裝語法
wget https://github.com/EnterpriseVE/eve4pve-autosnap/releases/download/0.1.8/eve4pve-autosnap_0.1.8_all.deb dpkg -i eve4pve-autosnap_0.1.8_all.deb
- 建立 vm ID: 115 每小時自動快照一次, 保留 24 份
eve4pve-autosnap create --vmid=115 --label='hourly' --keep=24 - 這樣每小時 VM 115 就會自動產生一份快照 參考 PVE 管理畫面
- 參考網址 :

CT Backup 出現 CT is locked (snapshot-delete) 的解決方式
- 設定每天自動備份, 結果某一天突然看到備份失敗, 紀錄出現類似以下的訊息
: ERROR: Backup of VM 115 failed - CT is locked (snapshot-delete) :
- 查看原因是前一天自動備份時出現異常, 導致目前這個 CT 155 是在 lock 狀態, 查看 Snapshots 也有一個 backup 的 snapshot, 無法手動刪除, 原因也是 snapshot-delete
- 可以在 PVE 主機端透過以下語法解開 lock 狀態: Exp. CT id=115
pct unlock 115 - 完成後就可以刪除 CT 115 的 snapshot 以及進行 backup
- 如果 unlock 之後, 還是因為 snapshot 持續造成異常 lock 且 snapshot-delete 也無法刪除
- 可以手動修改 /etc/pve/qemu-server/ or /etc/pve/lxc 內的 <vm_id>.conf 內, 移除 [snapshot] 段落
- 然後需要關閉 vm , 在透過 pve 啟動 vm 就可解決這問題
- 參考網址 :
CT 啟動失敗出現 run_buffer: 321 Script exited with status 2 的解決方式
- 更新 PVE 系統重開後, 發現部分 CT 無法正常啟動, 出現
run_buffer: 321 Script exited with status 2 lxc_init: 847 Failed to run lxc.hook.pre-start for container "1xx" __lxc_start: 2008 Failed to initialize container "1xx" TASK ERROR: startup for container '1xx' failed
- 只要在 PVE 主機內安裝 binutils 即可解決這問題
apt install binutils
- 參考網址 :
Replication 異常解決方式
- 設定 PVE Cluster 內使用 zfs 的 VM or CT 進行檔案定期(預設每 15 分鐘)複製至另外一台主機
- 當出現其中一個 replication 程序無法完成, 其餘程序就會全部無法進行 Exp. 100 出現
2019-11-24 01:30:00 100-0: start replication job 2019-11-24 01:30:00 100-0: guest => CT 100, running => 1 2019-11-24 01:30:00 100-0: volumes => local-zfs:subvol-100-disk-0 2019-11-24 01:30:01 100-0: freeze guest filesystem
之後的所有 Replication 程序就會因為這個程序卡住無法完成 參考PVE畫面
- 解決方式
- 將備份時間錯開, Exp 原本設定 1:30 備份要改成 1:25 參考PVE畫面
- 中斷正在 freeze 的程序
ps -ef | grep free kill <程序ID> root@nuc:~# ps -ef | grep free root 13352 11857 0 20:06 pts/8 00:00:00 grep free root 18221 18180 0 01:30 ? 00:00:07 /usr/bin/lxc-freeze -n 100 root 20692 2 0 19:55 ? 00:00:00 [kworker/u16:3-events_freezable_power_] root@nuc:~# kill 18180 18221 root@nuc:~# ps -ef | grep free root 15153 11857 0 20:07 pts/8 00:00:00 grep free root 20692 2 0 19:55 ? 00:00:00 [kworker/u16:3-events_freezable_power_]
- 可以看到下一個 Replication 程序就開始進行, 最後也會執行原本卡住的程序


PVE 主機啟用 iSCSI target(server) + ZFS
- 安裝與設定程序
- 建立 ZFS 預計提供給 iSCSI target 的儲存空間
- 透透過 PVE 1)建立 ZFS pool 或使用安裝時建立的 ZFS rpool
- ZFS 參考語法:
- zpool list : 查看有哪些 ZFS pool
- zfs list : 查看有哪些 ZFS dataset
- zfs destroy : 將不要的 ZFS dataset 刪除掉 Exp.
zfs destroy -r rpool/data/subvol-105-disk-1 - zfs create : 建立一個新的 ZFS dataset Exp. 建立 400G 命名 v400 的 dataset 執行語法:
zfs create -V 400g rpool/v400
- 安裝 iSCSI Target 服務
apt-get install tgt - 設定 iSCSI Target Exp.
- 儲存路徑 : 上面 zfs create 建立的 rpool/v400 對應路徑 - /dev/zvol/rpool/v400
- 命名 iqn.2018-09.everplast.net:v400
- 允許 iSCSI initiator(Client) 的 IP 範圍 : 10.168.0.0/24
- 不特別設定密碼與加密
- 編輯設定檔語法
- /etc/tgt/conf.d/ever_iscsi.conf
<target iqn.2018-09.everplast.net:v400> # Provided device as an iSCSI target backing-store /dev/zvol/rpool/v400 initiator-address 10.168.0.0/24 #incominguser tecmint-iscsi-user password #outgoinguser debian-iscsi-target secretpass </target>
- 啟動與設定 iSCSI Target 服務開機自動啟動
service tgt start systemctl enable tgt
- 參考網址 :
PVE 主機建立 ZFS Storage
- pve 5.2-8 之後開始可以由 WebUI 建立 ZFS
- 測試透過外接 USB 兩顆 1TB 硬碟建立 Mirror ZFS 的 Storage
- 需要將兩棵 USB 現有的 Partation 刪除才會出現在 Create ZFS 的未使用清單內
- RAID Level 選 Mirror
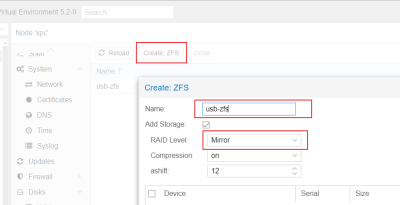
- 完成建立後透過選這新增 usb-zfs 的 detail 可以看到狀態
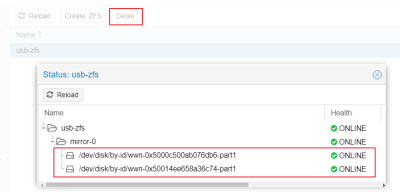
- 之後就可以在 Datacenter 建立 usb-zfs 的 Storage 提供放置 VM Image
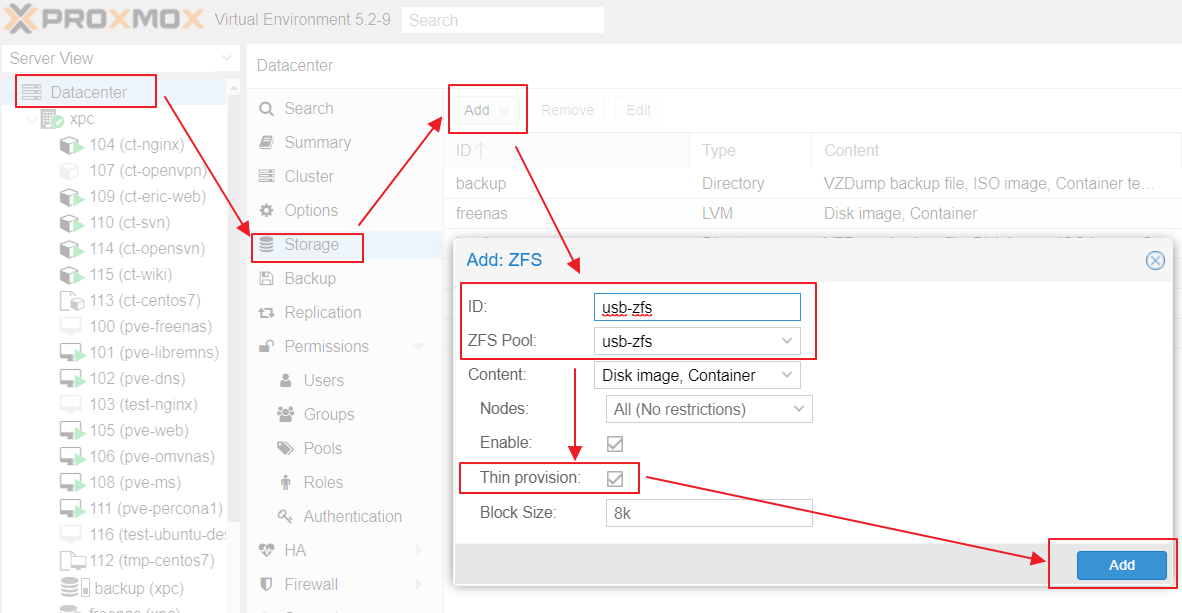
- 測試將一顆 USB 硬碟拔掉, 跑在上面的 VM 確實不會受到影響
- 將 USB 硬碟接回, 處理復原程序(必須在主機端下命令處理):
- 透過 WebUI 也可以了解目前的狀況
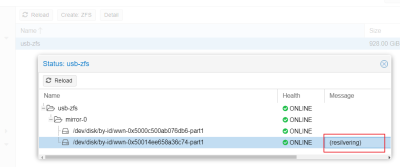




- 參考網址 :
Guest VM 安裝 Agent
- 安裝程序 :
- CentOS VM
yum install qemu-guest-agent systemctl start qemu-guest-agent
- Debian / Ubuntu VM
apt install qemu-guest-agent systemctl start qemu-guest-agent
- Alpine VM
apk add qemu-guest-agent修改 /etc/conf.d/qemu-guest-agent 設定 GA_PATH=“/dev/vport2p1”
: # Specifies the device path for the communications back to QEMU on the host # Default: /dev/virtio-ports/org.qemu.guest_agent.0 GA_PATH="/dev/vport2p1"
rc-update add qemu-guest-agent rc-service qemu-guest-agent restart
- Freebsd
pkg install qemu-guest-agent sysrc qemu_guest_agent_enable="YES" service qemu-guest-agent start
- Windows VM
- 先下載 virtio-win.iso 掛上 Windows 的 VM CD-ROM
- 進入光碟路徑內找到 virtio-win-gt-x64 與 guest-agent/qemu-ga-x86_64 進行安裝
- 重新啟動 Windows VM
- PVE 端設定 VM → Option → Qemu Agent → [v]Enabled
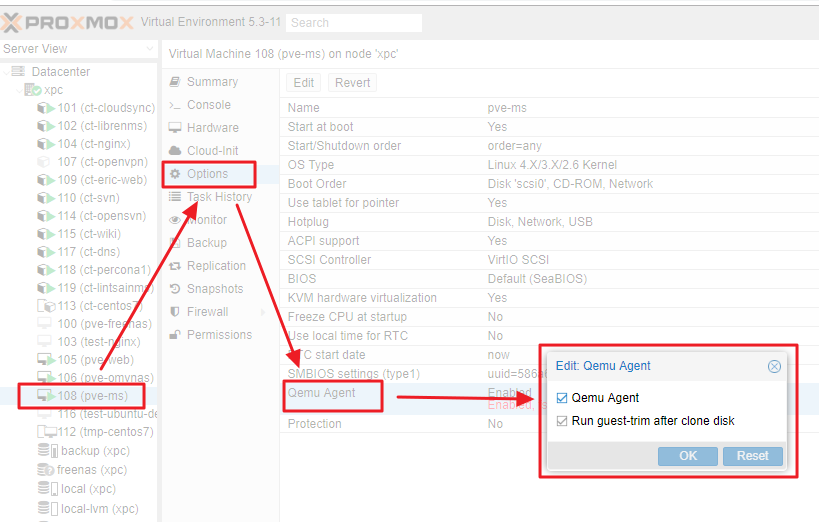
- 要透過 PVE 重起 VM 才會生效
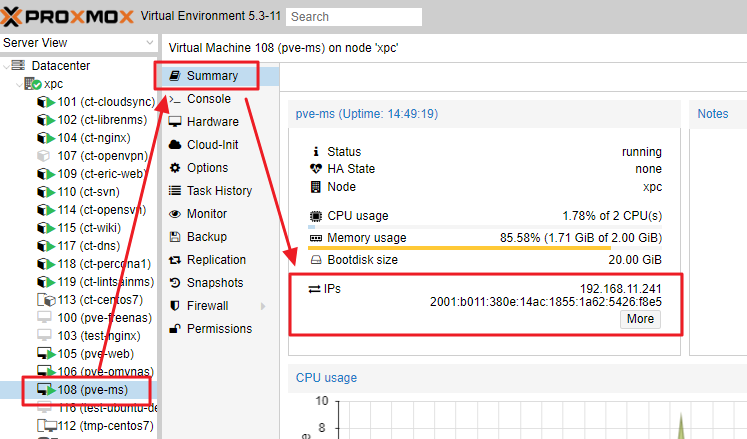
- VM → Summary → IPs 可以看到 VM 內分配的 IP


解決 VM 時間無法和 Host 同步問題
- 主要發生在 Alpine VM 內的系統時間無法和 PVE 主機時間相同的議題
- 解決方案 : 在 vmid.conf 內加入 args: -rtc clock=vm,base=utc 來解決 Exp. /etc/pve/qemu-server/111.conf
agent: 1 args: -rtc clock=vm,base=utc boot: order=scsi0;ide2;net0 cores: 2 cpu: x86-64-v2-AES ide2: none,media=cdrom memory: 2048 meta: creation-qemu=8.1.2,ctime=1702131932 name: pve-rproxy-internet net0: virtio=BC:24:11:8F:41:CE,bridge=vmbr0,firewall=1 numa: 0 onboot: 1 ostype: l26 scsi0: ssd-zfs:vm-111-disk-0,iothread=1,size=32G scsihw: virtio-scsi-single smbios1: uuid=595b1cc9-fbf0-4c16-a580-401bee86ac25 sockets: 1 tags: service vmgenid: 58a2ec03-e357-4aa9-8567-9e58ec447890
CT 忘記 root 密碼重設方式
- 執行方式
pct enter <VEID> passwd <new password> exit

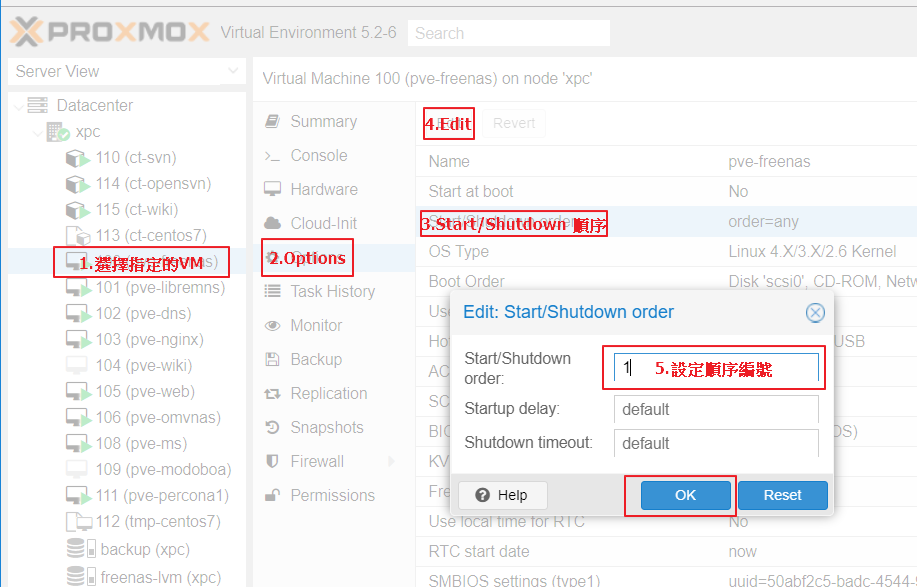
設定 VM 的開機與關機順序
- PVE Web UI → 選定 VM → Options → Start/Shutdown order → Edit

設定管理介面使用 Let's Encrypt 合法 SSL 憑證
- Datacenter → ACME 內
- 建立 Account : default 內容類似如下:
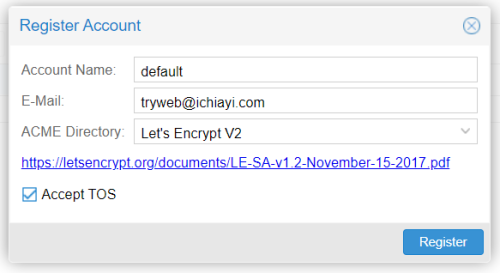
之前測試建立 default 之外都無法成功 - 建立 Challenge Plugins : Exp. ichiayi_com 這 Domain 因為是在 Cloudflare 代管, 所以可以透過 DNS 方式進行驗證 , 內容類似如下:
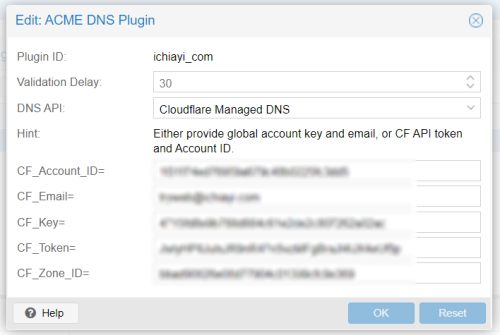
- 至 DNS 內建立每個 Node 的 domain name Exp. aac.ichiayi.com → 192.168.11.249
- 每個 Node 的 System → Certificates 內
- ACME 新增該 node 的 domain name 內容類似如下:
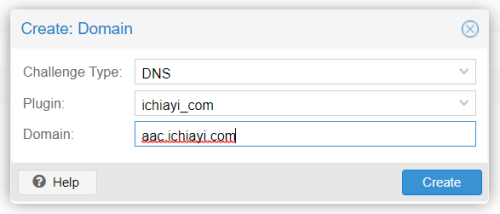
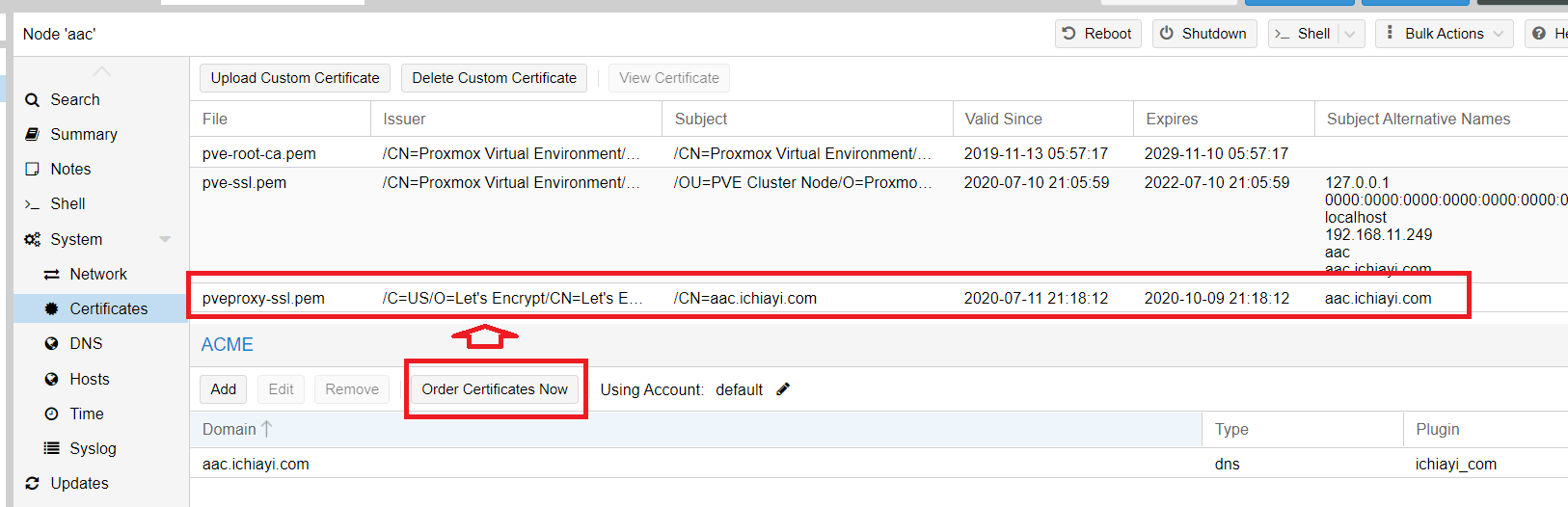
- 新增完成後就點下 Order Certificate Now 就會自動進行申請 SSL 憑證與佈署到 PVE 的自動程序, 如果都沒問題就可完成
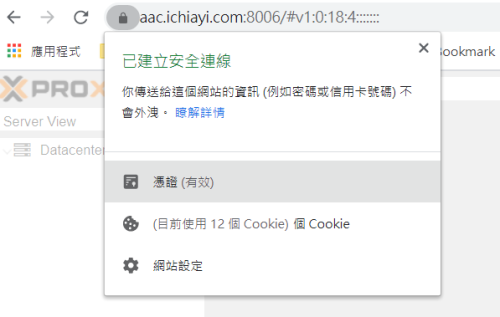
- 接著在瀏覽器網只用 domain name 就不會出現憑證警告訊息





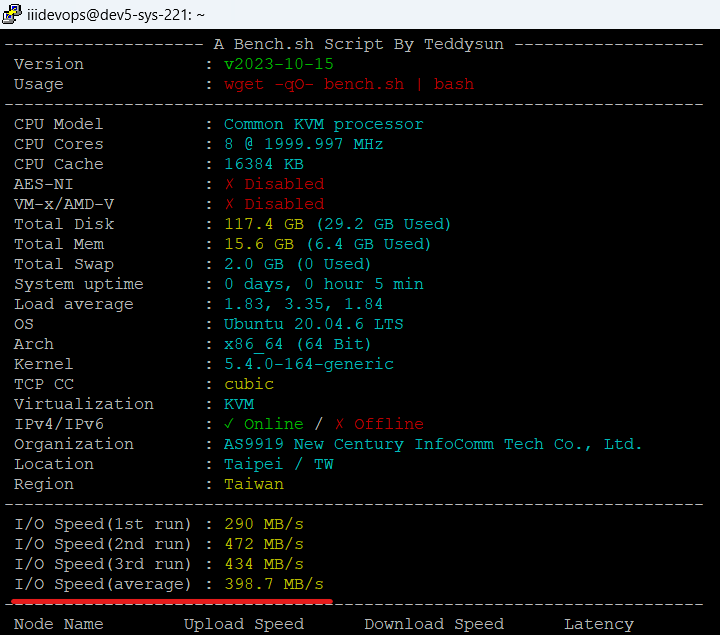
VM 寫入效能調整議題
- 原則上 Disk Cache 使用預設 none 模式即可(Host Page Cache:disabled, Disk Write Cache:enabled)

- 也可調整為 writeback 模式後(Host Page Cache:enabled, Disk Write Cache:enabled), 進入 VM 內使用 wget -qO- bench.sh | bash 進行效能測試來比對調整後的結果


Move Disk 出現 timeout 議題
- 當 VM Hard Disk 透過 Disk Action → Move Storage 到 NFS 的 Storage Exp. pvs-253-nfs 結果等 60 秒出現 timed out 類似以下的訊息
create full clone of drive scsi0 (zfs-raid:vm-106-disk-0) Formatting '/mnt/pve/pbs-253-nfs/images/106/vm-106-disk-0.qcow2', fmt=qcow2 cluster_size=65536 extended_l2=off preallocation=metadata compression_type=zlib size=536870912000 lazy_refcounts=off refcount_bits=16 TASK ERROR: storage migration failed: unable to create image: 'storage-pbs-253-nfs'-locked command timed out - aborting
- 主要的原因就是 pve-253-nfs 這 Storage 速度太慢, 無法在 60 秒內建立出 500G 的磁碟空間(preallocation).. 所以可以設定對這 storage 不要 preallocation, 作法如下
pvesm set pbs-253-nfs --preallocation off這樣針對 pbs-253-nfs 這 storage 就不會在搬移前進行 preallocation.
讓 PVE 6 安裝 CentOS7 的 CT 移轉至 PVE 7 的妥協做法
清除舊版 kernel 的做法
- 雖然每次升級後透過 apt autoremove 會自動移除掉不需要的舊版 kernel 但仍然會殘留一些不需要的 kernel 版本在系統內.. Exp. pve-kernel-5.4: 6.4-12 ..
- 所以可透過 tteck 提供的 Proxmox VE Kernel Clean 工具將 kernel 5.x 全部清除
bash -c "$(wget -qLO - https://github.com/tteck/Proxmox/raw/main/misc/kernel-clean.sh)"
PVE ISO 安裝無法啟動 XWindow 的解決方式
- 對於比較新的硬體可能 ISO 內還未支援 X driver, 所以會出現中斷在以下的訊息, 無法進入 GUI 安裝畫面
Starting the installer GUI - see tty2 (CTRL-ALT-F2) for any errors...按下 (CRTL-ALT-F2) 出現以下類似的錯誤訊息
: (EE) Fatal server error: (EE) Cannot run in framebuffer mode. Please spacify busIDs (EE) :
- 切回 Console 畫面編輯 X Driver config file
- 先以 lspci | grep -i vga 來確認 vga pci 編號
root@TN1-PVE-103:~# lspci | grep -i vga 00:02.0 VGA compatible controller: Intel Corporation Device a780 (rev 04)
- 編輯 config 檔案 Exp. /usr/share/X11/xorg.conf.d/my-vga.conf
Section "Device" Identifier "Card0" Driver "fbdev" BusID "pci0:00:02:0:" EndSection
- 重啟 XWindows
xinit -- -dpi 96 >/dev/tty2 2>&1
相關頁面
| 2023/12/18 11:50 | Jonathan Tsai | |
| 2023/10/19 21:50 | Jonathan Tsai | |
| 2023/07/02 16:52 | Jonathan Tsai | |
| 2022/07/30 19:56 | Jonathan Tsai | |
| 2022/07/08 16:19 | Jonathan Tsai | |
| 2022/01/10 10:41 | Jonathan Tsai | |
| 2022/01/08 21:40 | Jonathan Tsai | |
| 2021/08/16 14:58 | Jonathan Tsai | |
| 2021/07/31 18:55 | Jonathan Tsai | |
| 2021/07/31 18:37 | Jonathan Tsai | |
| 2021/03/09 22:23 | Jonathan Tsai | |
| 2021/01/16 23:52 | Jonathan Tsai | |
| 2020/07/29 10:21 | Jonathan Tsai | |
| 2020/07/21 11:22 | Jonathan Tsai | |
| 2020/07/18 16:35 | Jonathan Tsai | |
| 2020/07/15 17:11 | Jonathan Tsai | |
| 2020/07/10 15:12 | Jonathan Tsai | |
| 2020/07/03 17:19 | Jonathan Tsai | |
| 2020/05/13 13:13 | Jonathan Tsai | |
| 2019/11/03 12:31 | Jonathan Tsai | |
| 2018/07/25 11:36 | Jonathan Tsai | |
| 2018/06/22 21:28 | Jonathan Tsai |
1)
PVE 5.2-8 開始可以透過 UI 建立